[ES] JavaScript - String객체
오늘은 JavaScript의 String 객체에 대해서 알아보겠습니다.
length
문자열의 길이를 반환합니다.

예제

문자열의 길이만큼 for문이 반복하면서 문자열의 문자 하나하나를 출력하는 예제입니다.
indexOf
문자 혹은 문자열의 처음 찾은 인덱스 값을 반환합니다, 만약 해당 문자나 문자열을찾지 못한다면 -1을 반환합니다.
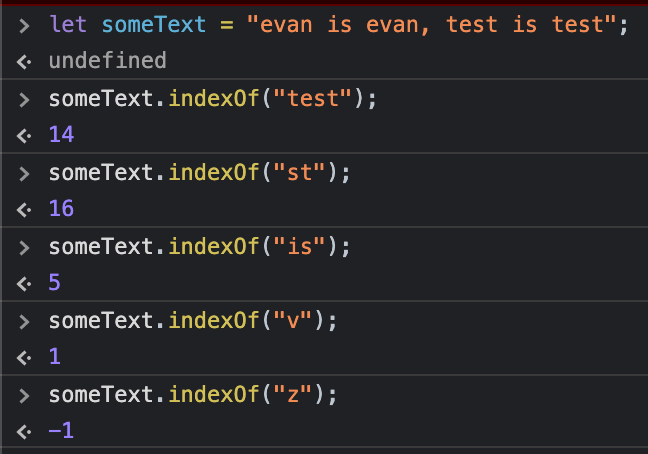
indexOf를 처음 사용한 시점부터 결과들을 분석해보면
첫번째는 "test"가 처음 등장한 인덱스의 값을 찾는것인데, "evan is evan,"바로 뒤에 "test"를 발견하여 이것을 처음으로 발견한 인덱스인 14를 반환해 줍니다.
두번째는 잘 알고있는 단어가 아닌 "test"문자열의 일부인 "st"를 찾는데 처음으로 발견된 곳은 역시 "evan is evan," 바로 뒤의 "test"의 "st"값이 시작되는 16을 반환합니다.
세번째는 첫번째와 같습니다.
네번째는 한글자도 가능하다는것을 보여주기위한 예제입니다.
다섯번째는 someText에 없는 문자를 의도적으로 찾게했는데 "z"는 없으므로 -1을 반환하는것을 알수있습니다.
예제

위의 예제는 찾는 문자열이 없을경우 음수(-1)을 반환하는 특징을 이용해서 조건문을 구성한 예제입니다.
lastIndexOf
위의 indexOf의 반대라고 생각하면됩니다. 찾고싶은 문자열을 처음부터가 아닌 끝에서부터 찾기 시작합니다. 찾았다면 찾은 단어의 인덱스 첫번째값, 못찾았다면 -1을 반환합니다.
예제

첫번째는 "test"가 문자열의 끝에서부터 찾아서 처음 등장한 인덱스의 값을 찾는것인데, 바로 나오는 "test is test"에서 강조된 test를 찾아 그 문자열의 첫 인덱스 값을 반환하는것을 알수 있습니다.
두번째는 "st"를 뒤에서부터 찾고있으며 16번째 인덱스에서 "st"를 찾을수 있습니다.
세번째는 첫번째와 같습니다.
네번째는 한글자도 가능하다는것을 보여주기위한 예제입니다.
다섯번째는 someText에 없는 문자를 의도적으로 찾게했는데 "z"는 없으므로 -1을 반환하는것을 알수있습니다.
lastIndexOf도 indexOf와 똑같은 예제를 활용했습니다.
search
찾고싶은 문자열 첫 인덱스를 반환합니다. indexOf와의 차이점은 search는 정규식을 통해 원하는 문자열을 찾을수도 있습니다.

제일 처음 예제를 보면 일부러 제가 indexOf안에 정규식을 넣어봤는데 분명히 someText안에는 "test"와 "evan"이라는 문자열이 있음에도 -1(값이없음)을 반환하는것을 볼수있습니다. 반면에 바로 아래 search 함수에서는 "test"와 "evan"이 발견된 첫 인덱스를 정상적으로 반환합니다. 이것이 indexOf와 search의 차이입니다. 또한 search도 역시 문자열을 발견하지 못하면 -1을 반환하는것을 알수있습니다. 슬래쉬 뒤에 ig의 뜻은 i는 (Ignore) 대소문자 구분을 안하겠다라는 뜻이고 g는 (global)의 약자로 문자열 전체에서 찾겠다는 말입니다. 자세한 정규식의 내용은 추후 다루겠습니다.
slice
문자열.slice(시작,끝)으로 사용하며 시작인덱스 ~ 끝인덱스 - 1까지 잘라 새로운 String을 만들겠다는 뜻입니다.

첫번째는 1번인덱스부터 4 - 1인덱스까지 문자열을 잘라 반환하겠다는뜻인데 1번인덱스의 v에서 부터 3(4-1)번 인덱스인 n까지를 잘라 반환하는것을 알수있습니다.
두번째는 slice함수가 마이너스 인덱스를 지원한다는것을 보여드리려고 한 에시입니다. slice함수는 마이너스 인덱스를 제공하지만 자바스크립트 배열은 0부터시작이므로 마이너스 인덱스가 없습니다. 따라서 someText[-1], someText[-2] 과 같은 것은 존재하지 않습니다.
substring
substring은 slice와 비슷하게 시작인덱스 ~ (끝인덱스 -1)까지의 부분 문자열을 반환합니다.
문자열.substring(시작,끝) 이때 끝은 생략가능하면 끝을 생략하면 시작부분부터 문자열의 끝까지의 부분문자열을 반환하겠다는 뜻입니다. 아래 예제를 통해 더 다양한 경우를 다뤄보겠습니다.

1번은 1~2인덱스까지의 문자열을 반환합니다.
2번의 경우처럼 시작과 끝의 숫자가 같게되면 빈문자열 ""을 반환합니다.
3번은 시작인덱스가 끝인덱스보다 큰 경우인데 이럴경우 시작과 끝의 인덱스가 서로 바뀌어 첫번째예시와 똑같이 동작하게됩니다 즉, subString(3,1) 은 subString(1,3)과 같이 변경되서 실행됩니다.
4번은 시작인덱스만 있고 끝인덱스는 생략한 경우인데 이럴경우 1번인덱스부터 문자열의 끝까지의 문자열을 반환합니다.
5번은 substring에서는 마이너스 인덱스가 불가능 합니다.
6번에서 시작 인덱스만 음수이고 끝 인덱스는 정상적인 문자열의 길이 범위안에 들어오게되면 -2(음수)는 자동으로 0으로 변경되어 첫인덱스부터 2(3-1)인덱스까지의 문자열을 반환합니다. 즉, 시작인덱스가 음수이면 이는 자동으로 0으로 바뀌어 실행됩니다.
7번은 끝 인덱스가 비정상적으로 큰 경우인데 이럴경우 끝 인덱스는 someText.length로 자동으로 바뀌어 실행됩니다 즉, 3번인덱스부터 문자열의 끝까지의 문자열을 반환합니다.
substr
substr은 MDN 공식홈페이지에서도 바람직하지 않은 특징을 가지고있다고 하여 사용처가 없어질 경우 공식홈페이지에서도 제거될 것이라고 나타내고있습니다. 링크
substr대신 substring을 사용합시다!
replace
원하는 문자열을 찾아서 바꾸고싶은 문자열로 바꾸는 함수인데 일반문자열뿐만 아닌 정규식도 사용가능합니다.

1번째와 2번째는 분명히 다른예시입니다.
1번째는 "evan"이라는 문자열을 찾아서 "Warrior"로 바꿔줍니다 이때 제일 처음 찾은 "evan"만 바꾸는것을 확인할수있습니다.
이에반해 2번째 예시는 정규식을 통해 replace를 사용한 예시인데 /evan/ig에서 g옵션때문에 글로벌하게(문자열전체에서) "evan"이라는 문자열을 모두 찾아 "Warrior"로 바꿔주는 모습을 볼수 있습니다.
toUpperCase, toLowerCase
이름에서 추측가능하듯이 문자열의 모든 문자를 대문자(toUpperCase) 또는 소문자(toLowerCase)로 바꾸어주는 함수입니다.

사용 예시는 위와 같습니다.
제가 좀더 차이점을 알기쉽게 표현하기위해
예제 텍스트 someText의 내용을 "Evan is evan, TEST is test"와 같이 대소문자를 섞어 문자열을 재구성하고 함수를 실행시켰습니다.
위의 함수들은 DB(Data Base)에서 요긴하게 사용할수 있는데 각각의 문자열 john, John, JOHN이 있을때 이 3가지를 한번에 가져오기위해서 toUpper혹은 toLower를 통해 대문자 혹은 소문자로 전부 통일 시킨후 가져올수 있습니다.
concat
concat은 concatenation의 약자이며 사전적 의미는 연결, 이음이라는 뜻을 가지고 있습니다.

위의 예시처럼 문자열을 원하는 문자를 기준으로 다른문자열과 합칠수 있습니다.
형식은 문자열.concat(중간에 이을 문자, 연결할 다른문자) 이며
첫번째는 공백을 기준으로 "Hello"와 "World!"를 연결시키고 있습니다.
두번째는 " I'm Evan "을 기준으로 "Hello"와 "World!"를 연결시키고 있습니다. (양 옆으로 공백이 있음에 유의합니다. 무슨 뜻을가진건 아니고 제가 그냥 넣은겁니다.)
trim
trim은 문자열 앞뒤로 공백을 제거해주는 함수입니다.

위의 예제처럼 문자열 앞에 의도적으로 공백을 많이주고 trim함수를 실행시켰는데 공백이 앞뒤로 모두 제거된 문자열을 반환하는것을 볼수있으며 이때 주의깊게 볼점은 white-space와 test사이의 공백이 있는데 이 공백은 사라지지 않았다는점입니다. 이처럼 공백을 무조건 없애는게 아닌 최초 맨 앞과 뒤의 공백들만 제거합니다.
padStart, padEnd
padStart와 padEnd는 우선 우리가 지정한 문자열을 원래 문자열 내용에 추가해 글자수를 맞춰주는 함수인데 padStart는 앞에서부터 추가하고 padEnd는 뒤에서부터 추가한다. 코드로 봅시다.

첫번째는 "go " << (공백포함)라는 길이가 3인 문자열을 "test"에 추가하는데 앞에서부터 추가한 문자열 결과를 반환해주고 있습니다.
두번째는 첫번째와 같은데 "go "라는 문자열을 뒤에서부터 붙혀주고 있습니다.
세번째는 padStart의 예시인데 또 DB와 연관된 예시를 들텐데 년,월,일 중에 월을 나타내는 데이터를 2글자 (04,05,06,12)로 통일 시키고싶을때 "4"라고 저장되어있는 한글자의 DB의 문자열을 "04" 이렇게 바꾸고싶을때 사용합니다 4,5,6이라는 한글자가 있다면 이것을 2글자의 04,05,06으로 바꿔주고 12는 원래 2글자였으므로 아무런 변화가 없습니다. 이렇게 모든 월에 해당되는 글자를 2글자로 통일시켜줄수 있습니다.
네번째는 padEnd의 예시입니다. 반대로 뒤에 0을 붙혀야할일이 있다면 사용하시면 될것 같습니다.
padStart, padEnd의 나만의 생각법
이 함수 두개는 문자열.padStart(글자수, 이어붙일문자열)과 같은 형식으로 되어있는데 최종결과들을 자세히 보면 결국 글자수에 해당하는 길이만큼의 문자열로 만들어주는것이므로 이미 저 글자수만큼의 길이를가진 문자열은 결과에 변화가 없고 글자수만큼의 길이를 가지지 못한 문자열만 결과에 변화가 생겼다고 생각을하니 조금 더 이해를 쉽게할수 있었습니다.
charAt
이 함수는 문자열의 특정위치에 있는 문자 한개를 반환합니다.

이렇게 "evan"이라는 문자열에서 1번째 인덱스에 위치한 "v"를 정상적으로 가져온것을 확인할수 있습니다.
split
이 함수는 문자열을 특정 기준이 되는 문자를 가지고 분리해줍니다.
가장 많이쓰는 예시로 공백을 기준으로, ,(콤마)를 기준으로 나누는 예시가 있습니다.

정리
이렇게 String 객체의 다양한 함수들을 알아보았는데 이것말고도 더있으며 정리한 함수들을 가지고 저보다 더 다양한 예시를 만들어내고 활용할수있습니다. 댓글을 통해 여러분들이 활용해본 예시들을 적어주시면 감사하겠습니다.